
生成AIのビジネスユースケースはどこにあるのか
— Fully Connected Tokyo 2025を前に考える ―

生成AIが社会に浸透し始めてから、まだわずか3年の間にChatGPTは8億人が使うようになり、日本でも「チャッピー」は高校生世代からも人気のようです。一方で、GPT5の案外マイルドなアップデートが気づかせてくれた様に、ファウンデーションモデルの開発競争は一段落し、ここにきて私たちは改めて問い直す段階に来ています。「この技術は、実際にどこまで企業の中で利用され、価値を生んでいるのでしょうか?」
採用の構造変化が示す変化の波
実際のところ、企業現場での価値の定着はまだら模様と言えますが、最近の雇用データからは、影響の輪郭が鮮明になりつつあります。たとえばエントリー層のソフトウェア職は明確に逆風で、SignalFireの2025年レポートは「エントリーレベル採用が崩壊」とまで表現しています。
(Blackstone’s Jon Gray on AI as the “Main Thing”)
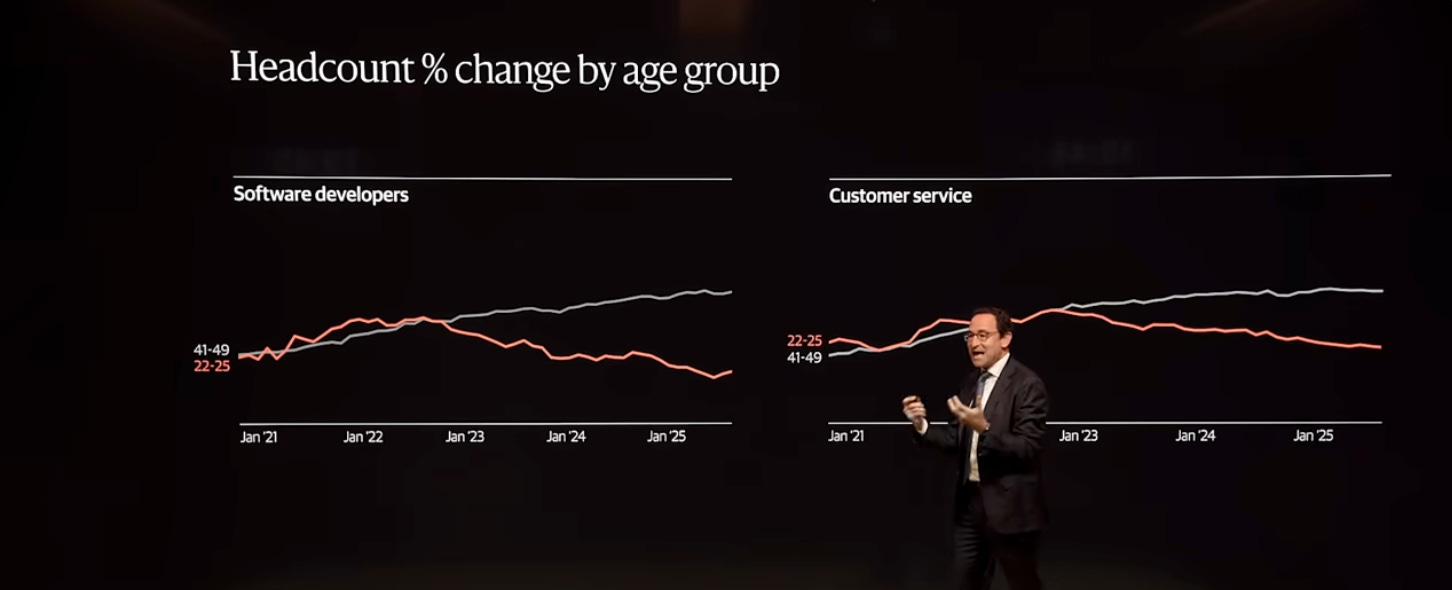
スタンフォード大学の研究では、ソフトウェアエンジニアや、カスタマーサービスなどAIに晒されている職種ほどエントリーレベル(22-25歳)の雇用が相対的に減少していることが示されています(上の図)。一方で上位熟練層の需要は堅実に推移している点が対照的です。定型的なコーディングはAIに頼り、設計・統合・評価・リスク判断に人間の専門性が集中し始めた、というパターンが見えてきています。
企業内部に目を向けると、「導入の広がり」と「価値化の隘路」が同時進行しています。BCGのAI at Work 2025は、管理職以上のAI利用が進む一方でフロントラインの習慣的利用は約5割で頭打ちになっていると報告。Deloitteのレポートでも、多くのPoCが本番・スケールに移行しきれていない現実を示しています。これからのAI導入成功の鍵は技術そのものより、業務再設計・評価設計・ガバナンスにあるのではないでしょうか。
技術進化の現在地:基盤モデルからアプリケーションへ
基盤モデル開発サイドの力学も変わりつつあります。GPUやデータを追加することによる汎用的大規模モデルの性能スケーリングは以前ほど大きく感じられなくなりました。特にB2Bにおいては複数の競合軸において様々なプレーヤーが戦略的に競い合っています。オープン系ではQwenやDeepSeekが台頭しその性能はトップモデルと数ヶ月に迫っています。MistralやCohereは企業や政府と組み、事業・目的特化モデルの開発を個社ごとに支援する動きを加速しています。開発者向けAPIの利用では、AnthropicがOpenAIに負けない勢いで成長しています。
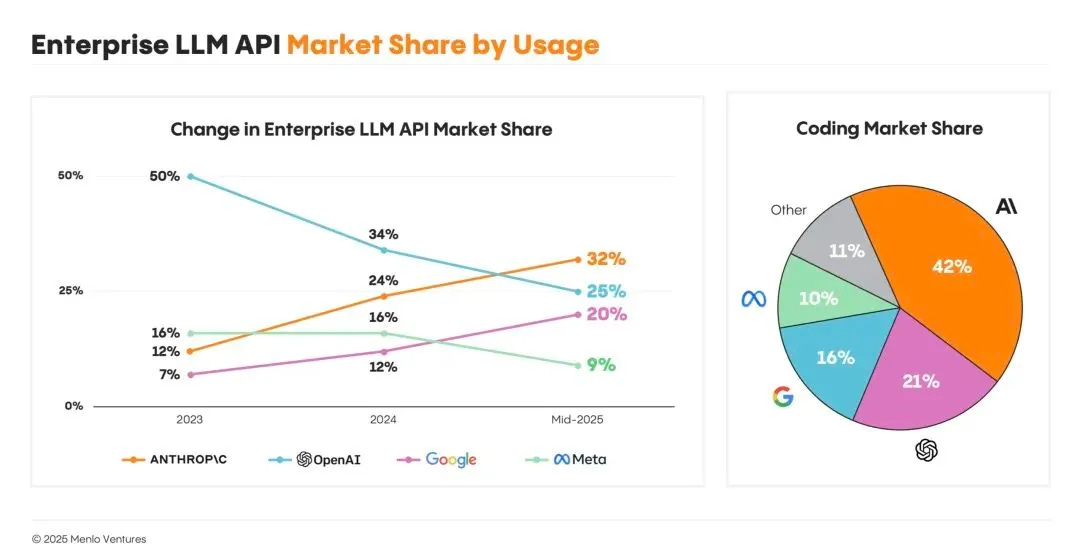
(AnthropicがEnterprise LLM APIで首位に成長)
一方のOpenAIは近年、Sora2(動画生成SNS)、Atlas(AIブラウザー)、Pulse(ニュースリーダー)など、消費者向けプロダクトを立て続けに発表しています。これもまた「汎用モデルの改良」から「AIアプリケーション開発」方向への転換を示しています。
エンタープライズ導入の現状:点在する成功と広がる模索
こうした背景の中で、私たちが関心を持っているのは企業がどのようにAIを導入しようとしているかです。これは大きく二つの方向性に分けられます:
社内横断の“生産性の底上げ”的取り組み
検索・要約・ナレッジ整備・議事生成・コード補完・QA支援など、広く薄く効く知識労働の効率化を目的とした「社内活用」。多くの企業で試行が進み、生産性向上に一定の成果を上げているが、企業に特化した業務や、クリティカルなリスクの伴う業務の自動化を任せられる性能には至りません。
特定ユースケースに最適化されたAIアプリケーション/エージェントの開発
より専門的な業務プロセスを自動化・最適化する試み。例えばサプライチェーン計画、保全予知、請求審査など、やがてはあらゆる業務が対象となることが期待されているが、まだ実験段階にあるものが多く、精度・安全性・再現性の確立にはさらなる経験とノウハウの蓄積が必要です。
これからの価値創出の源泉、特に日本企業にとっての主戦場は、このように各社の差別化につながるような業務特化型AIの開発だと考えていますが、場合によってはこれは非常に長い時間のかかるプロセスにもなりえます。例えば、自動運転の開発は今でこそ実運用化に漕ぎ続けた企業が出てきましたが、長年開発を続けてきたほとんどの企業は実現できていません。
Fully Connected Tokyo 2025 ― AI開発の最前線を現場視点で俯瞰する
これらの動向を2日間にわたる豊富なアジェンダで、現場視点で俯瞰できるのが、今週開催のFully Connected Tokyo 2025(https://fullyconnected.jp)です。主にWeights & Biasesのユーザー企業を中心に下記のようなスピーカーの登壇を予定しています:
モデル開発者サイド:Anthropic、Alibaba Cloud(Qwen開発チーム)、Mistral、Liquid AI、日本からはSakana AIやLLM.jpなどが登壇。各社の最先端研究と、今後の事業戦略を語ってくれます。
実装企業サイド:Toppan、NAVER、日立、ダイキン、NHKなど、実際にエンタープライズユースケースを推進している企業が登壇。特に私が注目しているのはダイキンの比戸氏による「空調特化LLM」の継続学習事例です。
政策・支援機関/プラットフォーマー:経済産業省、日本ディープラーニング協会、Google、AWSそしてWeights & Biasesが登壇し、産業・技術・倫理の三方向から議論をリードする。
ハンズオン/実践セッション:Weights & Biases、Upstage、カラクリ、Sakana AI、電通総研などが、実際のビジネス課題に合わせた生成AIエージェントの開発手法をワークショップ形式で共有。
ハイプの先にある実装における経験値を元に、これから日本企業がAIを導入することで深い事業インパクトを生み出していくための参考になるようなイベントを目指して準備をしてきました。
PoCを量産することではなく、業務や社会課題の文脈で持続的に運用できる仕組みを築くためのヒントにしていただけましたら幸いです。